Получение элементов с рандомными символами с помощью регулярок
Экспорт полученных результатов в таблицу Excel
Заключение
1. Оглавление
Всем здарова, в этом гайде мы будем писать парсер объявлений subito.it (итальянский авито) и затем результат помещать в таблицу Excel на Python. Я уверен, что после этой статьи появится куча платных парсеров, но зато люди в разделе "Ищу софт" найдут свой заветный парсер
Лучшей IDE для кодинга на Python я считаю PyCharm (она бесплатная), поэтому код пишу в ней. Открываем свою IDE и создаем новый проект и затем переходим или создаем главный файл (main.py)
Так как парсеров по моему гайду можно написать абсолютно на все сервисы, поэтому для каждого сайта будем делать свой файл и класс (но уже продолжим в этом) Создадим класс SubitoParser и напишем __init__ функцию, где создается наша сессия requests и присваиваются ей заголовки и юзерагент:
4. Получение элементов с рандомными символами с помощью регулярок
Отлично, теперь местные антиботы будут меньше нас детектить и после создаем основную функцию Get, где будет весь функционал парсера и вставляем такой код (я его объясню ниже):
И так, ты спастил кучу непонятного тебе кода, теперь я объясню что делает библиотека BeautifulSoup4. Именно на этой библиотеке мы делаем весь функционал парсера (получение контента из html тегов). Т.к. мой парсер работает по списку товаров, то на вход мы даем ему ссылку со списком товаров. Затем парсер должен обработать каждый товар в списке и получить его URL, по которому он получает все важные значения следующим запросом.
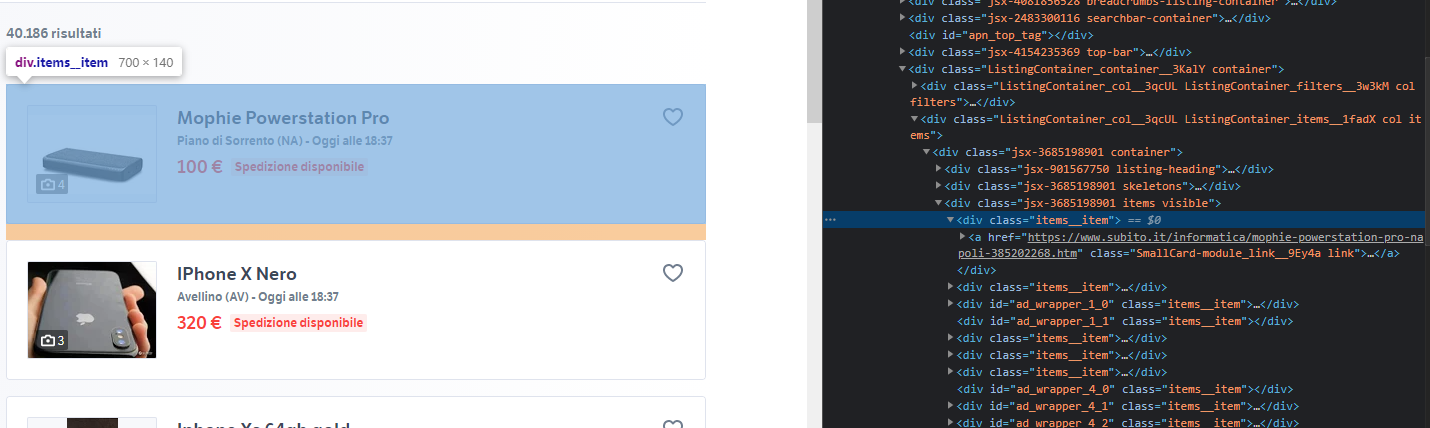
А как обнаружить этот список товаров? Просто нажимаем ПКМ по одному из товаров и по иерархии элементов поднимаемся выше, пока не найдем что-то типо такого:
И на этом скриншоте видно, что все товары имеют класс items__item, а ссылка на товар - это самый первый a тег, поэтому объявляем BeautifulSoup на полученный контент по ссылке, в цикле for ищем все div'ы с классом items__item. Делаем обёртку try - except, если товар не так спарсился или сервис выдал ошибку.
А теперь скорее всего самое сложное для многих, если перейти по товару и просмотреть код элемента названия товара, то там будет куча бесполезного текста:
Т.е. после каждого класса идет рандомный текст (это борются с парсерами), но для них печально то, что это обходится одной строчкой, а именно - регулярные выражения. Мы просто берем один класс, который УНИКАЛЬНЫЙ именно для этого элемента, убираем все лишнее и получается
Код
re.compile('^classes_price.*')
Теперь какой бы рандом не был вокруг этого класса, мы будем получать именно элемент с ценой на товар. Думаю объяснять как работает findAll не нужно, ибо English, my friend! И сразу сохраняем в локальный словарь все полученные переменные и добавляем этот словарь в список, который был объявлен ранее.
5. Экспорт полученных результатов в таблицу Excel
И теперь переходим в предпоследнюю часть гайда - сохранение полученных товаров в таблицу Excel
Внимательно вставляем следующий код ПОСЛЕ цикла for (где мы доставали наши товары):
Код
if all_ads is not None: table_name = 'ultimate-sorter-subito-' + str(self.id) +'.xlsx' workbook = xlsxwriter.Workbook(table_name) worksheet = workbook.add_worksheet() for i in range(len(all_ads)): j = all_ads [i]worksheet.write(i, 0, i) worksheet.write(i, 1, j["title"]) worksheet.write(i, 2, j["price"]) worksheet.write(i, 3, j["created"]) worksheet.write(i, 4, j["description"]) worksheet.write(i, 5, j["location"]) worksheet.write(i, 6, j["seller-name"]) #worksheet.write(i, 7, j["seller-active"]) worksheet.write(i, 7, j["url"]) workbook.close() return os.path.abspath(table_name) else: return "error"[/i]
Т.к. я этот парсер делал телеграм ботом, то название файла с таблицей состоит у меня с ID юзера, чтобы не было путаницы.
Объявляем Workbook, добавляем туда страницу и проходимся по каждому элементу списка (они же наши полученные товары), добавляя построчно значения из словаря. Затем закрываем таблицу (сохраняем) и возвращаем полный путь до файла с результатом.
6. Заключение
На этом можно гайд заканчивать, чтобы спарсить товары достаточно написать новую функцию __main__, откуда уже и вызвать SubitoParser(url, uid).Get() ( url - ссылка страницу с товарами и uid - идентификатор юзера или просто рандомные цифры, буквы)
Вот и всё, пишем свои парсеры, не продаем, ибо каждый для них по моей базе пишется за 10 минут и живем счастливо. Также держите все сервисы, на которые я уже смог реализовать парсеры